Még a Facebook sem érti a Facebook algoritmusait
A Facebook hírcsatornájának - az a tartalom, amelyet akkor lát, amikor telefonjáról vagy laptopjáról bejelentkezik a Facebookra - jóvoltából az összes kézforgatás, amely a „hamis hírek” látványosságából származik, egy dolog teljesen világossá vált. Még a Facebook sem érti a Facebookot.
És ez a probléma egy olyan algoritmikus mesterséges intelligenciára (AI) támaszkodva, amelyet az évek során különféle fejlesztők és programozók százai építettek (vagy pontosabban összeillesztve).
Mindez világossá vált számomra az elmúlt napokban, amikor elgondolkodtam azon dolgokon, amelyeket a legutóbbi HealtheVoices 2017 konferencián tanultam, és miután Farhad Manjoo kiváló cikkét olvastam a Facebookról New York Times Magazine.
A konferencián a Facebook képviselője kissé csalódott (és időnként szinte ellenséges) kérdező tömeggel nézett szembe azzal kapcsolatban, hogy az egészségügyi aktivistaként és szószólóként írt dolgok miért tűntek ritkán a mások Facebook-hírcsatornáiban. Az egyetlen módja annak, hogy elköteleződni látszott, azt mondták aznap a közönség tagjai, hogy megvásárolta azt a Facebookon keresztül (egy fizetett mechanizmus révén, amelyet egy bejegyzés „fellendítésének” neveznek).
A Facebook képviselőjének nem volt válasza ezekre a kérdésekre arról, hogy miért nem mutatják be a hírcsatornájukban a látszólag jó minőségű, jó tartalmat. Mégis minden egyes résztvevő, akivel beszéltem - szenvedélyes, elkötelezett egészségvédők - problémának tekintette a Facebookot. De még a Facebook sem tudta elmagyarázni, hogyan lehetne kijavítani.
Ez nem csoda. A Times magazin cikke rávilágított a „miértre”. A Facebook hírcsatorna-algoritmus azonban átlagosan 2000 darab lehetséges tartalmat válogat, valahányszor egy ember először tölti be a Facebookot és minden frissítéskor.
Annyi változó megy bele abba a bonyolult, sötét és szabadalmaztatott rendezési algoritmusba, hogy még a Facebook sem tudja megválaszolni, hogy miért jelenik meg vagy nem jelenik meg valaki hírcsatornájában. Nagyon hasonló fájdalomról van szó, amelyet a webmesterek már régóta éreztek a Google-lal és a keresési indexelő algoritmusukkal való foglalkozásban.
Az a tény, hogy az algoritmus könnyen megkerülhető az emberek hírcsatornájához való egyszerű hozzáférés megvásárlásával, nem meglepő. Nagy része annak, amiért a Facebook évről évre ennyit keres. Még a legrosszabb minőségű tartalom is továbbjuthat állítólag személyre szabott hírcsatornájába.
Hírcsatorna: Még folyamatban lévő munka
Azt gondolhatnád, hogy ennyi év kemény munka, odafigyelés, fejlesztői órák és ezen algoritmus kutatása után néhány alapvető dolog rendbe jön. De két legutóbbi anekdotából kiderül, mennyivel messzebb kell még mennie a Facebook dicséretes AI-jának.
Az első a koncertmém, amely 2017. április végén vette kézbe a Facebook hírcsatornáját. Ebben a mémben a résztvevők 10 koncertet sorolnak fel, amelyeken életük során részt vettek, de az egyik hamis. Az illető barátainak a feladata, hogy észrevegyék a hamis koncertet, amelyen még nem vettek részt, és megjegyzést fűztek hozzá.
A kezdeti gondolatom, amikor először láttam ezt a felbukkanót, a következő volt: "Kit érdekel?" mert őszintén szólva nem érdekel, hogy a barátaim milyen koncerteken vettek részt. Ha tényleges beszélgetést folytattam volna a barátaimmal a „látott koncertek” témában, az nagyszerű lehet. De beszélgetés kezdőként nem érzékeltem, mert kék színű - társadalmilag kapcsolatban áll semmi. Tehát elértem a „Hide this post” pontot az elsőtől, amit a hírfolyamomon láttam.
Ez segített megállítani a tartalom beáramlását a hírcsatornámba a következő napokban? Egyetlen sem. A következő két napban nem kevesebb, mint egy tucat ilyen kérdést láttam elárasztani a hírcsatornámban (még azután is, hogy rákattintottam még legalább kettőre a "Hírek elrejtése" gombra). Mindez nulla érdeklődéssel bírott. Ennyit a Facebook mesterséges intelligenciájáról.
A második a Bloom County. Óriási rajongó vagyok, és örültem, amikor a Berkeley Breathed újra rajzolni kezdett. Várom minden napot, amikor egy új képregény jelenik meg a hírcsatornámban. Titokzatos módon a Facebooknak erről fogalma sincs. Néhány héttel ezelőtt abbahagyták a képregényeinek bemutatását, annak ellenére, hogy a legtöbbjükre figyelmesen rákattintottam, hogy könnyebben olvashassam őket kibővített formában.
Hogyan eredményezheti ennyi kattintás a „nem érdekli, ne jelenjen meg ennek a felhasználónak” címkét? A Facebook nem tudott válaszolni erre a kérdésre, ha akart, mert fogalma sincs arról, hogy a hírcsatorna-algoritmusa hogyan működik - vagy nem működik - az egyes felhasználók számára. Ez vicces lenne, ha nem lenne olyan nagy baj. A Pew Research Center adatai szerint az amerikaiak több mint fele a Facebook-on kapja hírét.
Visszajelzési űrlapok, amelyek kevés visszajelzést adnak a felhasználóknak
A Facebook állítása szerint rengeteg problémát képes felmérni (és javítani tud), ha a felhasználók csak gyakrabban használják visszajelzési űrlapjaikat. De a felhasználók utálják visszajelzéseket küldeni a Facebook-ról - csak visszajelzési rendszerük szar.
A Facebook visszajelzési űrlapjai nagyon kevés visszajelzést adnak a felhasználóknak, és ehelyett értékelik, hogy a felhasználókat egy sor „Lásd, hogyan lehet ezt te magad megoldani, idióta” kérdésre vezetve, amelyek egyértelműen úgy tűnik, hogy mindig azt sugallják, hogy a felmerülő problémák többsége a tiéd. javítás - nem a Facebooké. A formák végén nincs ember, és nincs olyan emberi válasz, amelyet valaha is megkapna. Ez az embertelen definíció. Ironikus egy olyan vállalat számára, amely úgy látja, hogy „globális közösséget épít”, mindenki társadalmilag jobban összekapcsolódik. Hogyan teheti ezt meg egy vállalat, miközben kerüli a felhasználóival való emberi kapcsolattartást?
Az AI olyan összetett, az embereknek segíteniük kell
Sok fejlesztő azt mondja magának, hogy az AI nagyjából képes megoldani minden emberi problémát, ha elegendő változót, adatkészletet és módosítást kap. De amit a Facebook egyértelműen megmutatott, hogy bármit is tesz a hírcsatorna problémájának megoldása érdekében, az AI nem működik sok-sok ember számára.
Senki sem érzi úgy, hogy a Facebook még csak hallgat is. Mint korábban megjegyeztem, az egészségvédők és az aktivisták, akikkel a konferencián beszéltem, azt mondták, hogy nem hallgatják meg őket. Úgy tűnik, hogy a közösségi médiatársaságok, mint a Facebook, nem érdeklik őket. A hírkiadók zárt Facebook-csoportjában pedig naponta hallom a csalódottságot arról, hogy hány elismert hírszervezet mélyreható, oknyomozó újságírói cikkei sanyargatják a Facebookot fizetett ösztönzés nélkül. Eközben egy szellős „5 csodálatos, gyors és egyszerű módja a nyári barnulásnak” dobható cikk több találatot kap, mint Trump Google által a „Hogyan lehet kijavítani…” lekérdezés.
Válaszfotók a mai AI-n
Az Apple által dicsért Sirit gyakran tartják az AI hasznos példájaként, amely a mai modern világban működik. De amikor ezt a cikket írtam, azt mondtam: "Hé Siri, mondd el Nancynek, hogy szeretem."
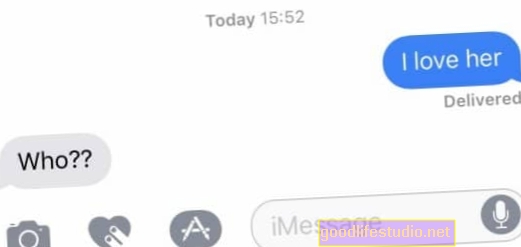
Siri végtelen bölcsességével helyt adta az üzenet címzettjét (szerencsére, mivel csak egy Nancyt ismerek). De a szövege a következő volt: „Szeretem.” Sirinek nyilvánvalóan nem volt értelme a mondatom tényleges értelméről, és ehelyett kezdetleges szűrőkkel állapította meg, hogy a kapcsolattartóimban lévő személynek egy szöveget szeretnék küldeni a szó szerinti üzenettel: „Szeretem őt”.
Ez az AI szintje, amellyel ma együtt dolgozunk olyan nagy technológiai vállalatoknál, mint a Facebook, a Google és az Apple - kissé hasznos, de minőségében és megvalósításában frusztrálóan egyenetlen.
Nagyon remélem, hogy a Facebook ezt kitalálja, mert minden nap egyre kevésbé találom magam, mivel egyre kevésbé releváns az én tényleges érdekek és a mindennapi élet. Lehet, hogy ma kisebbségben vagyok, de gyanítom, hogy ez megváltozik, ha a Facebook nem oldja meg hamarosan ezeket a releváns és érdekes problémákat.
Lábjegyzetek:
- Ez az egyik oka annak, hogy a konferencia Facebook-előadói gyakran felmerülnek ilyen sok kérdésben - ez az egyetlen emberi kapcsolat, amelyet legtöbbünk valaha is megélt ezzel a technológiai óriással. [↩]